推しが歌う最近の神曲のススメ
推し駆動○○ Advent Calendar 2022 - Adventarの11日目担当のほっとここあです。
通勤中とかに聴いてる推しの最近の神曲を少し書きました。
何が悪い
虹夏...好きだ...
MVはもちろん、踊りたくなるようなメロディで聞いていて気持ちいい。
虹夏ちゃんが楽しそうに元気よく歌っているイメージができてとても好き。
明るいバンドの曲って感じで最近電車で毎日聴いてる。
夢への一歩
歩夢...好きだ...
正直ここまでキャラクターと声優がマッチしてることってないんじゃないかってくらい合ってる。
「諦めなければ夢は逃げない」みたいな歌詞、何故か大人になってからの方が心に響く。まさに歩夢という名前にぴったりなキャラクター、歌だと思います。
最近あまり聴いてなかった素直に可愛いアイドルの曲という感じがして好きです。元気出る。
トウキョウ・シャンディ・ランデヴ
花譜ちゃん...好きだ...
アニメのキャラクターという立ち位置ではないですが、歌声が圧倒的にずば抜けているのと感情のこもり方が凄いので推しになっちゃった。
アップテンポだったりラップ調になったりと何回聴いても飽きない。
曲も斬新な感じで声も力強いので聴きごたえあるしワクワクする。
あと花譜ちゃんのラップはめっちゃ聴きごたえあるから他の歌も聴いてほしい。
さくらんぼ
※(一応補足)原曲は大塚愛さんの曲です。
英子の元気な歌声で聴くさくらんぼは神です。
男子はみんな大塚愛さんのさくらんぼが好きだけど恥ずかしくて言えないです。
僕も隠れて100回くらい聞きました。それを推し歌う訳ですから良いに決まってますよね。MVも今どきって感じで、何回も再生してしまいます。
はじまりのセツナ
明日ちゃん(推し)達が歌う曲です。
出だし聴いただけでから「あ、これ神曲だわ」って思った。
MV見なくても青春ものって分かるくらい爽快なメロディと素敵な歌詞で本編見てなくても涙出そうなレベル。もちろんMVもクオリティが高くて明日ちゃんたちの楽しさが伝わってきますね。
水色のSunday
シンプルに可可ちゃんの声が可愛いのと、曲のテンポが独特で凄い落ち着く。
散歩中とかに聴くととても癒されるし日曜日に聴こうものなら朝から晩まで散歩しそう。いやマジで。
声と曲がこんなに合ってることってあるんだなーって思いました。
終わりに
もっとあるけど書き切れません。
短いですが見てくれてありがとうございました。
Unity入門してみた
イメージビューアー(予定)
これをちょっと改良します。coming soon...
フルスイング(部誌)読み辛えわってなって作成 pic.twitter.com/khVux98jAX
— ほっとここあ☕️@就活中 (@hotococoasister) 2021年4月4日
翻訳付きの通話Webアプリ作って遊ぶ
作った画面
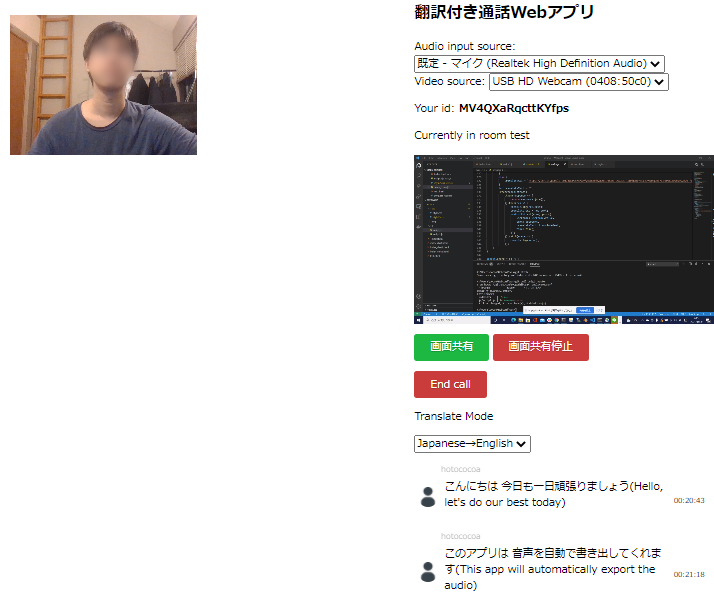
まだデプロイしてないのでぼっちのデモになってる。
作った理由
Web Speech API割と精度いいなぁというのと、バカなので外国人と話すとき翻訳あると助かるなぁと思い組み合わせることにしました。
Web Speech APIで音声を認識→認識した音声をあらかじめGASで作っておいたgoogle翻訳の結果を返してくれるAPIを立ててそこに流す
というふうにしました。認識結果と翻訳内容はfirebaseのrealtime databaseに逐次保存されます。
あと画面共有機能の資料があまりなくて実装に苦労した。
感想
無料っていいね!
DeepL APIにしたらもっといいんだろうなと思いつつお金はかけたくないので保留
Gridsomeでポートフォリオ作ってみた
github.com unruffled-fermi-be1e3f.netlify.app
作った理由
就活でポートフォリオの提出がめちゃくちゃ多かったので作りました。
Vueはインターンシップで少しだけ触っていて、今回Markdownとかで書こうとかではないので別に使う必要はないけど、どうせなら何か知らないものも使ってみようと思ってVueのSSGフレームワークGridsomeを使ってみました。
Vue.jsのSSGフレームワークGridsomeはすごいぞ!! - Qiita
vuetifyを使った実装
vueでの開発はvuetifyを使うと楽なのでインストールしておきます。
$ npm install --save vuetify $ npm install --save-dev webpack-node-externals
gridsome.server.jsを以下のように設定します。
const nodeExternals = require('webpack-node-externals'); module.exports = function (api) { api.chainWebpack((config, { isServer }) => { if (isServer) { config.externals([ nodeExternals({ allowlist: [/^vuetify/] }) ]) } }) api.loadSource(({ addCollection }) => { // Use the Data Store API here: https://gridsome.org/docs/data-store-api/ }) api.createPages(({ createPage }) => { // Use the Pages API here: https://gridsome.org/docs/pages-api/ }) }
vuetifyの使い方は簡単で公式ドキュメントの実装でやりたいことと似ているものを探してそれを使います。 vuetifyjs.com
例えば今回では
Skillsの項目のとこ
カード・コンポーネント — Vuetifyタイムライン
タイムライン・コンポーネント — Vuetify
をコピーしてきて、不要な部分や直したいところは微調整します。
タイムラインのところの実装はEducation.vueを見ると若干変えてはいますが、ほぼ一致していることが分かります。
gridsome-portfolio/Education.vue at master · SyogoShibuya/gridsome-portfolio · GitHub
こんな感じで高速で実装できます。
デプロイ
Netlifyというものを用います。 新しくnetlify.tomlというファイルを作成し、以下のように記述します。
[build] publish = "dist" command = "gridsome build"
残りは以下のサイトのように書いたソースをGithubにあげ、NetlifyとGithubを連携させればデプロイ完了です。
Gridsomeを利用して簡単なサイトを作成しよう
感想
無料っていいね。